Course catalog
Categories
Showing 1-9 of 9 items.
 احتمال و آمار برای یادگیری ماشین و علم داده
(Mitalearn-303872)
احتمال و آمار برای یادگیری ماشین و علم داده
(Mitalearn-303872)
- 8 hours 24 minutes
- متوسط
- Release date: 23 June 2026
- Author: Luis Serrano
درباره این دوره:
به تازگی برای سال 2024 به روز شده است! Mathematics for Machine Learning and Data Science یک برنامه آنلاین پایه است که توسط DeepLearning.AI ایجاد شده و توسط Luis Serrano تدریس می شود. در یادگیری ماشینی، شما مفاهیم ریاضی را از طریق برنامه نویسی به کار می برید. و بنابراین، در این تخصص، مفاهیم ریاضی را که با استفاده از برنامه نویسی پایتون یاد می گیرید، در تمرینات آزمایشگاهی عملی به کار خواهید برد. به عنوان یک زبان آموز در این برنامه، برای موفقیت به مهارت های برنامه نویسی پایتون اولیه تا متوسط نیاز دارید. پس از اتمام این دوره، شما قادر خواهید بود: • با استفاده از مفاهیم احتمال، متغیرهای تصادفی، و توزیع احتمال، عدم قطعیت ذاتی در پیشبینیهای مدلهای یادگیری ماشین را توصیف و کمی کنید. • درک بصری و شهودی خواص توزیعهای احتمال رایج در یادگیری ماشین و علم داده مانند توزیعهای برنولی، دوجملهای و گاوسی • روشهای آماری رایج مانند برآورد حداکثر احتمال (MLE) و حداکثر تخمین پیشینی (MAP) را برای مشکلات یادگیری ماشین اعمال کنید. • ارزیابی عملکرد مدل های یادگیری ماشین با استفاده از تخمین های بازه ای و حاشیه خطاها • استفاده از مفاهیم آزمون فرضیه های آماری در آزمون های رایج در علم داده مانند آزمون AB • تجزیه و تحلیل داده های اکتشافی را روی یک مجموعه داده برای یافتن، اعتبارسنجی و کمی کردن الگوها انجام دهید. بسیاری از مهندسان یادگیری ماشین و دانشمندان داده در زمینه ریاضیات به کمک نیاز دارند، و حتی تمرینکنندگان با تجربه نیز میتوانند از کمبود مهارتهای ریاضی عقبمانده شوند. این تخصص از آموزش نوآورانه در ریاضیات استفاده میکند تا به شما کمک کند تا سریع و شهودی یاد بگیرید، با دورههایی که از تجسمهای ساده برای پیگیری استفاده میکنند تا به شما کمک کنند تا ببینید که چگونه ریاضیات پشت یادگیری ماشین واقعاً کار میکند. ما به شما توصیه می کنیم سطح ریاضی دبیرستان (توابع، جبر پایه) و آشنایی با برنامه نویسی (ساختارهای داده، حلقه ها، توابع، دستورات شرطی، اشکال زدایی) داشته باشید. تکالیف و آزمایشگاهها در پایتون نوشته شدهاند، اما این دوره تمام کتابخانههای یادگیری ماشینی را که استفاده میکنید معرفی میکند.
Related Skills

پایتون برای علم داده
(Mitalearn-327145)
- 10 hours 27 minutes
- مبتدی
- Release date: 23 June 2026
- Author: Fractal Analytics Academy
درباره این دوره:
استاد پایتون برای علم داده با پروژه های عملی. پانداها، آمار و تجسم را برای حل مشکلات تجارت در دنیای واقعی بیاموزید. ایجاد مهارتهای آماده برای کار در بحث و گفتگوی دادهها، تجزیه و تحلیل دادههای اکتشافی (EDA) و ترسیم نمودار با matplotlib/seaborn—بدون نیاز به تجربه قبلی. این دوره آموزشی مبتدی شما را از طریق پاکسازی داده های نامرتب، استفاده از آمار توصیفی و استنباطی و تهیه مجموعه داده ها برای یادگیری ماشین راهنمایی می کند. شما تجزیه و تحلیل هایی را طراحی خواهید کرد که به سؤالات تجاری پاسخ می دهند، بینش ها را با تصاویر متقاعد کننده ارتباط برقرار می کنند و ارزیابی های چالش برانگیز را کامل می کنند که با سناریوهای محل کار هماهنگ هستند. در پایان، با اطمینان دادهها را در پانداها دستکاری میکنید، گردش کار را خودکار میکنید و داشبوردهایی میسازید که ذینفعان آن را درک کنند. سفر مبتنی بر داده خود را شروع کنید و داده های خام را به تصمیم گیری تبدیل کنید.
Related Skills
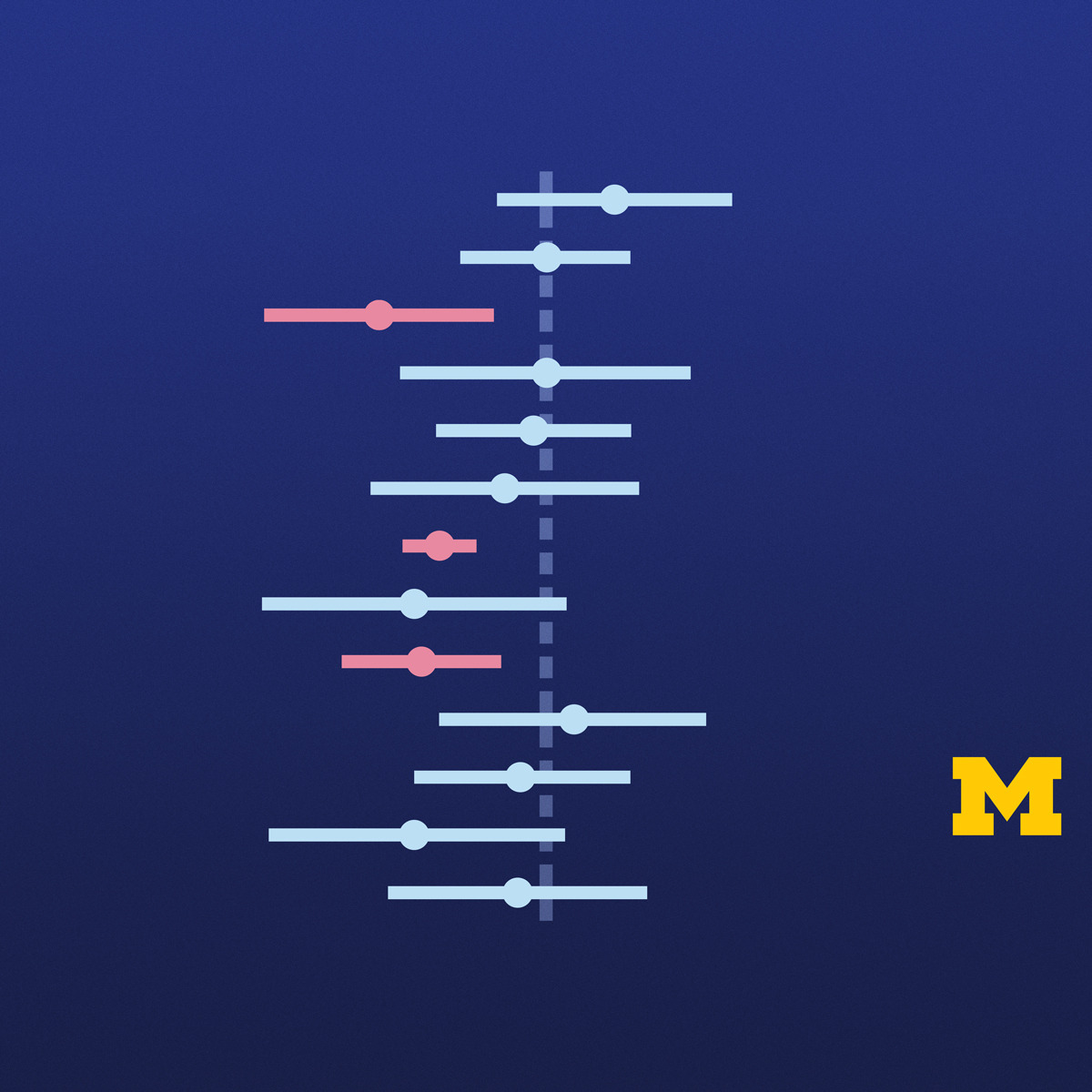
تجزیه و تحلیل آماری استنباطی با پایتون
(Mitalearn-332721)
- 5 hours 4 minutes
- متوسط
- Release date: 23 June 2026
- Author: Brenda Gunderson,Brady T. West,Kerby Shedden
درباره این دوره:
در این دوره، ما اصول اولیه استفاده از داده ها برای تخمین و ارزیابی نظریه ها را بررسی خواهیم کرد. ما هم داده های طبقه بندی شده و هم داده های کمی را تجزیه و تحلیل خواهیم کرد، از تکنیک های یک جمعیت شروع می کنیم و برای مقایسه دو جمعیت گسترش می دهیم. ما یاد خواهیم گرفت که چگونه فواصل اطمینان ایجاد کنیم. ما همچنین از داده های نمونه برای ارزیابی اینکه آیا یک نظریه در مورد مقدار یک پارامتر با داده ها مطابقت دارد یا خیر استفاده خواهیم کرد. تمرکز اصلی بر تفسیر مناسب نتایج استنباطی خواهد بود. در پایان هر هفته، فراگیران آموخته های خود را با استفاده از پایتون در محیط دوره به کار می گیرند. در طول این جلسات مبتنی بر آزمایشگاه، فراگیران از طریق آموزش هایی با تمرکز بر مطالعات موردی خاص برای کمک به تقویت مفاهیم آماری هفته، که شامل غواصی عمیق بیشتر در کتابخانه های پایتون از جمله Statsmodels، Pandas و Seaborn است، کار خواهند کرد. این دوره از محیط نوت بوک Jupyter در Coursera استفاده می کند.
Related Skills
تجزیه و تحلیل داده های اکتشافی برای یادگیری ماشینی
(Mitalearn-270280)
- 4 hours 52 minutes
- متوسط
- Release date: 23 June 2026
- Author: Joseph Santarcangelo,Svitlana (Lana) Kramar
درباره این دوره:
این اولین دوره در گواهینامه حرفه ای یادگیری ماشین آی بی ام شما را با یادگیری ماشین و محتوای گواهینامه حرفه ای آشنا می کند. در این دوره به اهمیت داده های خوب و با کیفیت پی خواهید برد. شما تکنیک های متداول برای بازیابی داده های خود، پاکسازی آن ها، اعمال مهندسی ویژگی ها و آماده سازی آن ها برای تجزیه و تحلیل اولیه و آزمایش فرضیه را خواهید آموخت. در پایان این دوره شما باید بتوانید: بازیابی داده ها از چندین منبع داده: SQL، پایگاه داده NoSQL، API ها، Cloud توصیف و استفاده از تکنیک های رایج انتخاب ویژگی و مهندسی ویژگی ویژگی های دسته بندی و ترتیبی و همچنین مقادیر از دست رفته را کنترل کنید از تکنیک های مختلفی برای تشخیص و مقابله با موارد پرت استفاده کنید توضیح دهید که چرا مقیاس بندی ویژگی مهم است و از انواع تکنیک های مقیاس بندی استفاده کنید چه کسانی باید این دوره را بگذرانند؟ این دوره، دانشمندان مشتاق داده را که علاقه مند به کسب تجربه عملی با یادگیری ماشین و هوش مصنوعی در یک محیط تجاری هستند، هدف قرار می دهد. چه مهارت هایی باید داشته باشید؟ برای استفاده حداکثری از این دوره، باید با برنامه نویسی در محیط توسعه پایتون و همچنین درک اساسی حساب دیفرانسیل و انتگرال، جبر خطی، احتمالات و آمار آشنا باشید.
Related Skills
تست فرضیه با پایتون و اکسل
(Mitalearn-334285)
- 24 minutes
- متوسط
- Release date: 23 June 2026
- Author: Gerald S. Brown,Kishore K. Pochampally
درباره این دوره:
در بازار کار امروزی، رهبران برای رقابتی بودن نیاز به درک اصول اساسی داده ها دارند. یک روش ضروری برای درک تجارت و تجزیه و تحلیل، آزمون فرضیه است. این دوره کوتاه که توسط اساتید متخصص دانشگاه تافتز طراحی شده است، مبانی آزمون فرضیه میانگین جمعیت و نسبت جمعیت را با استفاده از Excel و Python برای محاسبات آموزش می دهد. شما همچنین قضیه حد مرکزی را که برای آزمایش فرضیه ضروری است، کشف خواهید کرد. برای به پایان رساندن دوره، با ایجاد طرحی برای آزمایشی در محل کار خود که از آزمون فرضیه استفاده می کند، مهارت های جدید خود را به کار خواهید گرفت.
Related Skills

شانس چیست؟ احتمال و عدم قطعیت در آمار
(Mitalearn-361621)
- 1 hours 37 minutes
- متوسط
- Release date: 23 June 2026
- Author: Jennifer Bachner, PhD
درباره این دوره:
این دوره بر این تمرکز دارد که چگونه تحلیلگران می توانند اعتمادی را که به یافته های خود دارند اندازه گیری و توصیف کنند. این دوره با مروری بر قوانین و مفاهیم کلیدی احتمال که بر محاسبه معیارهای عدم قطعیت حاکم است، آغاز می شود. سپس این ایدهها را برای متغیرها (که بلوکهای سازنده آمار هستند) و توزیعهای احتمال مرتبط با آنها اعمال میکنیم. نیمه دوم دوره به محاسبات و تفسیر عدم قطعیت می پردازد. ما در مورد چگونگی انجام آزمون فرضیه با استفاده از آمار آزمون و فواصل اطمینان بحث خواهیم کرد. در نهایت، نقش آزمون فرضیه را در زمینه رگرسیون، از جمله آنچه که میتوانیم و نمیتوانیم از اهمیت آماری یک ضریب یاد بگیریم، در نظر خواهیم گرفت. در پایان دوره، شما باید بتوانید یافته های آماری را به صورت احتمالی مورد بحث قرار دهید و عدم قطعیت یک تخمین خاص را تفسیر کنید.
Related Skills
قدرت آمار
(Mitalearn-335985)
- 5 hours 4 minutes
- پیشرفته
- Release date: 23 June 2026
- Author: Google Career Certificates
درباره این دوره:
این چهارمین دوره از هفت دوره در گواهی تحلیل داده های پیشرفته گوگل است. در این دوره، خواهید فهمید که چگونه متخصصان داده از آمار برای تجزیه و تحلیل داده ها و به دست آوردن بینش های مهم استفاده می کنند. شما مفاهیم کلیدی مانند آمار توصیفی و استنباطی، احتمال، نمونه گیری، فواصل اطمینان و آزمون فرضیه را بررسی خواهید کرد. همچنین یاد خواهید گرفت که چگونه از پایتون برای تجزیه و تحلیل آماری استفاده کنید و مانند یک متخصص داده، یافته های خود را به اشتراک بگذارید. کارمندان Google که در حال حاضر در این زمینه کار میکنند، با ارائه فعالیتهای عملی که وظایف مرتبط را شبیهسازی میکنند، به اشتراک گذاشتن نمونههایی از کارهای روزانهشان، و کمک به شما در تقویت مهارتهای تجزیه و تحلیل دادهها برای آماده شدن برای حرفهتان، شما را در این دوره راهنمایی میکنند. فراگیرانی که هفت دوره در این برنامه را تکمیل می کنند، مهارت های مورد نیاز برای درخواست برای مشاغل علوم داده و تجزیه و تحلیل داده های پیشرفته را خواهند داشت. این گواهی مستلزم آگاهی قبلی از اصول، مهارتها و ابزارهای تحلیلی پایه است که در گواهی تجزیه و تحلیل دادههای Google پوشش داده شده است. در پایان این دوره، شما: -کاربرد آمار در علم داده را شرح دهید -از آمار توصیفی برای خلاصه کردن و کشف داده ها استفاده کنید محاسبه احتمال با استفاده از قوانین اساسی داده های مدل با توزیع احتمال -کاربرد روش های مختلف نمونه گیری را شرح دهید -محاسبه توزیع های نمونه -فواصل اطمینان را بسازید و تفسیر کنید -آزمون های فرضیه را انجام دهید
Related Skills

کاربردهای تجاری آزمون فرضیه و تخمین فاصله اطمینان
(Mitalearn-213228)
- 3 hours 54 minutes
- مناسب همه
- Release date: 23 June 2026
- Author: Sharad Borle
درباره این دوره:
فواصل اطمینان و آزمون فرضیه ابزارهای بسیار مهمی در جعبه ابزار آمار کسب و کار هستند. تسلط بر این موضوعات به افزایش تصمیم گیری تجاری شما کمک می کند و به شما امکان می دهد میزان "ریسک" یا "عدم اطمینان" را در فرآیندهای مختلف تجاری درک و اندازه گیری کنید. این سومین دوره در زمینه تخصصی "آمار و تجزیه و تحلیل کسب و کار" است و این دوره با معرفی فواصل اطمینان و تست فرضیه دانش شما را در مورد آمار کسب و کار ارتقا می دهد. ابتدا به صورت مفهومی این ابزارها و کاربرد تجاری آنها را درک می کنیم. سپس محاسبات مختلفی را برای ساخت فواصل اطمینان و انجام انواع مختلف آزمونهای فرضیه معرفی میکنیم. اینها توسط برنامه های کاربردی آسان انجام می شود. برای انجام موفقیت آمیز تکالیف دوره، دانش آموزان باید به نسخه ویندوز Microsoft Excel 2010 یا جدیدتر دسترسی داشته باشند. لطفاً توجه داشته باشید که نسخه های قبلی مایکروسافت اکسل (2007 و قبل از آن) با برخی از توابع اکسل که در این دوره توضیح داده شده اند سازگاری ندارند. هفته 1 ماژول 1: فاصله اطمینان - مقدمه در این ماژول به صورت مفهومی خواهید فهمید که فاصله اطمینان چیست و چگونه ساخته می شود. ما بلوک های ساختمانی مختلف برای فاصله اطمینان مانند توزیع t، آماره t، آمار z و فرمول های مختلف اکسل آنها را معرفی خواهیم کرد. سپس از این بلوکهای سازنده برای ایجاد فواصل اطمینان استفاده خواهیم کرد. موضوعات تحت پوشش عبارتند از: • معرفی t-distribution، توابع اکسل T.DIST و T.INV • درک مفهومی فاصله اطمینان • آمار z و آمار t • ایجاد فاصله اطمینان با استفاده از آماره z و آماره t هفته 2 ماژول 2: فاصله اطمینان - برنامه های کاربردی این ماژول کاربردهای تجاری مختلفی از فاصله اطمینان را ارائه می دهد، از جمله برنامه ای که در آن از فاصله اطمینان برای محاسبه اندازه نمونه مناسب استفاده می کنیم. ما همچنین با یک برنامه، فاصله اطمینان برای نسبت جمعیت را معرفی می کنیم. در پایان ماژول ما شروع به معرفی مفهوم تست فرضیه می کنیم. موضوعات تحت پوشش عبارتند از: • کاربردهای فاصله اطمینان • فاصله اطمینان برای نسبت جمعیت • محاسبه اندازه نمونه • آزمون فرضیه، مقدمه هفته 3 ماژول 3: آزمون فرضیه این ماژول تست فرضیه را معرفی می کند. شما می توانید منطق پشت آزمون های فرضیه را درک کنید. چهار مرحله برای انجام یک آزمون فرضیه معرفی شده است و شما می توانید آنها را برای آزمون فرضیه برای میانگین جمعیت و همچنین نسبت جمعیت به کار ببرید. تفاوت بین آزمون های فرضیه دم تک و دو آزمون فرضیه دم و همچنین خطاهای نوع اول و دوم مرتبط با آزمون های فرضیه و راه های کاهش چنین خطاهایی را خواهید فهمید. موضوعات تحت پوشش عبارتند از: • منطق آزمون فرضیه • چهار مرحله برای انجام آزمون فرضیه • آزمون فرضیه تک دم و دو دم • دستورالعمل ها، فرمول ها و آزمون کاربرد فرضیه • آزمون فرضیه برای نسبت جمعیت • خطاهای نوع اول و دوم در یک فرضیه هفته 4 ماژول 4: آزمون فرضیه - تفاوت در میانگین در این ماژول، شما از آزمون های فرضیه برای آزمایش تفاوت بین دو داده مختلف استفاده می کنید، به این گونه آزمون های فرضیه، آزمون های تفاوت در میانگین می گویند. ما سه نوع تفاوت در آزمون میانگین ها را معرفی می کنیم و آنها را در برنامه های مختلف تجاری اعمال می کنیم. همچنین کادر محاوره ای اکسل را برای انجام چنین آزمون های فرضیه ای معرفی می کنیم. موضوعات تحت پوشش عبارتند از: • معرفی آزمون فرضیه تفاوت در میانگین • کاربردهای آزمون فرضیه تفاوت در میانگین • فرض واریانس برابر و نابرابر و آزمون t زوجی برای تفاوت میانگین ها. • برخی از برنامه های کاربردی دیگر
Related Skills
مقدمه ای بر علم داده و یادگیری اسکییت در پایتون
(Mitalearn-329236)
- 1 hours 30 minutes
- مبتدی
- Release date: 23 June 2026
- Author: Sabrina Moore,Rajvir Dua,Neelesh Tiruviluamala
درباره این دوره:
این دوره به شما یاد می دهد که چگونه از قدرت پایتون و هوش مصنوعی برای ایجاد و آزمایش فرضیه استفاده کنید. ما از ابتدا شروع می کنیم، و قبل از فرو رفتن در برخی از برنامه های کاربردی غنی تر آن برای آزمایش فرضیه ایجاد شده، چند پایتون پایه برای علم داده را یاد می گیریم. ما برخی از مهمترین کتابخانهها را برای تجزیه و تحلیل دادههای اکتشافی (EDA) و یادگیری ماشینی مانند Numpy، Pandas و Sci-Kit یاد خواهیم گرفت. پس از یادگیری برخی از تئوری (و ریاضیات) پشت رگرسیون خطی، خط لوله کاملی از خواندن دادهها، پاکسازی آنها و اعمال یک مدل رگرسیون برای تخمین پیشرفت دیابت را بررسی میکنیم. در پایان دوره، شما یک مدل طبقه بندی را برای پیش بینی وجود/عدم بیماری قلبی از داده های سلامت بیمار اعمال خواهید کرد.